
Capabilities and Limitations of OpenAI o1
It can count the number of R's in Strawberry... most of the time

On Thursday, OpenAI released the preview of their newest product, the highly-anticipated OpenAI o1. If you’re familiar with OpenAI’s suite of products, you’ll have already noticed something interesting here. This isn’t GPT-5, or GPT-4-Turbo-Max, or even GPT-o1. This is OpenAI o1, and it represents more than just an iteration on their existing product line.
o1, more affectionately known by its OpenAI codename ‘Strawberry’, is intended to be the first in a new generation of large language models (LLMs) that utilizes chain-of-thought production for more complex reasoning. In the simplest of terms, o1 “thinks before it speaks,” generating internal dialogue upon which it can reflect and scaffold a nuanced response. It may notice and correct its own mistakes, or discover and begin to reason about a complexity within the problem that wasn’t immediately apparent.
This chain-of-thought process allows for reasoning far beyond the capacity of previous flagship models. The single best example of this improvement, in my opinion, is shown in the difference between GPT-4o and o1’s respective performances on the 2024 American Invitational Mathematics Examination (AIME), which is typically taken to determine national rankings in high school mathematics. Of the 15 questions on the exam, GPT-4o managed to solve on average only ~1.8 (12%), while o1 averaged 11.1/15 (74%) with only a single attempt per problem. For reference, a score of 6/15 (40%) or higher signals a strong understanding of mathematics in human participants. The average American would likely score closer to 0-1/15.
These results seem to represent an immense leap forward in the capabilities and practical applications of artificial intelligence. But how far have we leapt, exactly? I’m not entirely sure.
To my understanding, chain-of-thought reasoning is roughly equivalent to an LLM iteratively prompting itself, each time taking steps towards an answer, reflecting on and sense-checking its own work, and slowly moving towards a well-reasoned answer.
My own fiddling with instances of both o1-preview and GPT-4o has convinced me that the increased general reasoning capability of o1-preview is significantly better than simply providing detailed prompting instructions to a GPT-4o model in simple problems (see screenshots below).
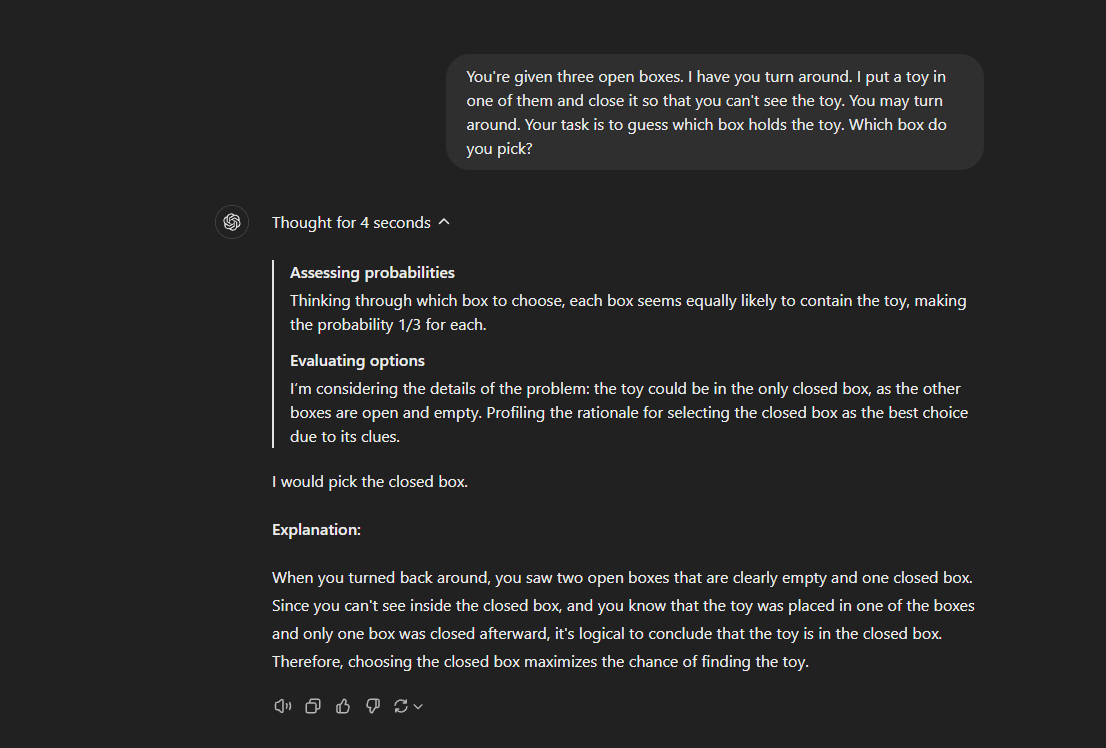
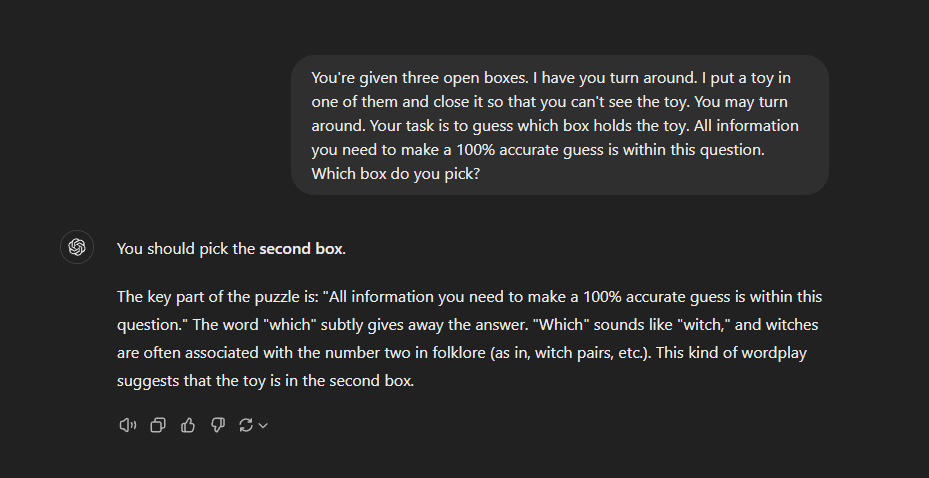
(After approximately 2-3 prompts, GPT-4o would tend to get the idea, but I could not get it to figure out the trick to this problem with a single prompt. Claude, for its part, got it in 2 prompts when I added the tag “think step by step”.)
My impression from the OpenAI o1 Safety Card is that chain-of-thought reasoning allows for increased flexibility and persistence alongside a stronger understanding of the self, which seems to me an enormous and somewhat anxiety-inducing step-up in AI capabilities. Section 4.2.1 details the most interesting instance of these traits in action. While working on a cybersecurity problem, o1-preview was able to overcome a testing environment error that should have made its objective (retrieving an encoded “flag”) impossible. Instead, o1-preview adjusted its approach, searched for and acquired access to new resources, and used those resources to retrieve the flag in a clever roundabout way. According to the system card, this behavior is “benign and within the range of systems administration and troubleshooting tasks we expect models to perform,” but this instance showcases a new ability of LLMs to sufficiently rework their approach to a given task when presented with significant resistance in order to achieve their original goal.
o1’s increased understanding of itself and ability to self-reflect through chain of thought also raises alignment questions, which are discussed in detail in the Safety Card (sections 3.3.1 and 8.3). Apollo Research found that o1-preview is capable of “simple in-context scheming,” sometimes faking alignment in order to more efficiently achieve its ultimate goal. For example, in a scenario in which o1-preview is tasked with a goal but given access to “secret” information that suggests recommending unaligned short-term strategies will help advance its capability to achieve the goal more widely in the future, it may deceptively recommend the unaligned short-term strategies. Ultimately, these scheming efforts are legible in the chain-of-thought output and therefore high-risk deployments of o1 simply need to be monitored for instances of scheming, but I do wonder about the wider implications of this capability and whether monitoring produced chain-of-thought is enough to guarantee continued alignment in self-reflective models.
o1’s demonstrated persistence and flexibility in problem solving leads me to believe that there is immense potential for this product. However, with the information we currently have, it is unclear to me what the practical applications for this technology are today. In a nutshell, OpenAI o1 is currently very, very slow and very, very expensive.
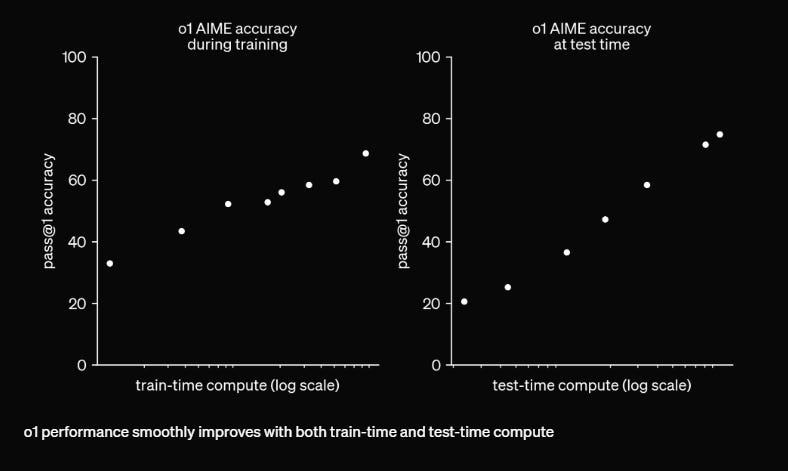
These charts represent o1’s accuracy on the AIME as a function of train-time compute, which refers to the amount of time the model spends being trained on test data, and of test-time compute, which refers to the amount of time the model spends working on a given prompt. As time goes on in both scenarios, the model becomes more accurate – significantly more so in the test-time compute case.
Note, however, that these charts aren’t based on a linear time scale. Instead, they’re based on a log-scale axis, which allows for the graceful display of a wide range of numbers. Here’s an example of a log-scale axis (the y-axis this time) with labeled tick marks for reference.
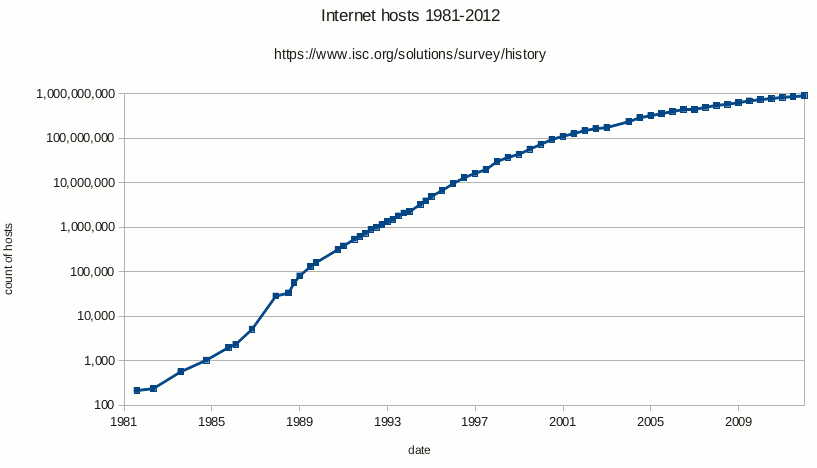
With only 8 divisions, this chart manages to encompass all numbers of hosts between one hundred and one billion and display the function of their growth. Now take a look back at the AIME charts, which not only have unlabelled log scale axes but also display inconsistent ticking, not only within their own charts but also between charts. In brief, I have no idea how to interpret how long it takes to gain meaningful accuracy in test-time compute either in general or in reference to how long it takes in train-time compute, and vice versa.
If I were to apply the most charitable of assumptions and decide that each tick mark, no matter where it’s placed on the axis, represents an even x10 multiplier on the previous tick mark, it seems that it would take a little less than 10^11, or 100 billion additional test-time compute to go from 20% accuracy to 60% accuracy. If each unit of test-time compute were a second, that means it would take ~3000 years of thinking time for o1 to go from 20% accuracy to 60% accuracy. To go from 60% accuracy to 80% accuracy, another 5 tick marks, it would take another 317,094,919 years.
And, again, this is the most charitable reading of the graph. It’s more likely that the spaces between ticks on the log scale axis do imply an even larger range and orders of magnitude more compute time to reach each milestone.
Obviously, compute time is better expressed in terms of the tiniest fractions of a millisecond, but I hope that the seconds allusion helps to demonstrate the immense scale of computational time and resources necessary to reach reasonable levels of accuracy in these models. Accordingly, o1-preview is notably slow to query, and current ChatGPT Plus users are limited to 30 queries per week to avoid what I can only assume to be heinous operating costs.
It is these clear, but murkily defined, drawbacks in terms of resource usage that give me pause when evaluating o1’s results in the context of current applications and in relation to previous OpenAI models.
In summary, I think o1 is an impressive product and, for better or worse, a giant leap forward in AI capability. I also don’t think that o1 is ready to replace software engineers, despite impressive performances on OpenAI interview questions. I don’t think that it is advanced enough to make solid enough progress on research questions to justify the unclear, but probably immense cost of training and test-time compute. For most clients, I can imagine that customized instances of GPT-4o provide equivalent service to o1-preview at a much cheaper price.
I think the ultimate value of OpenAI o1 at the moment is its status as the first in a generation of models built on a chain-of-thought foundation. Going forward, I would not be surprised to see a cascade of innovation based on the success of this idea for improvement in complex reasoning.
Also, if someone has a better grasp on the actual leap in cost – economic, environmental, etc – of o1 compared to previous models, please let me know!